MK-UNet: Multi-kernel Lightweight CNN for Medical Image Segmentation
Paper Abstract
In this paper, we introduce MK-UNet, a paradigm shift towards ultra-lightweight, multi-kernel U-shaped CNNs tailored for medical image segmentation. Central to MK-UNet is the multi-kernel depth-wise convolution block (MKDC) we design to adeptly process images through multiple kernels, while capturing complex multi-resolution spatial relationships. MK-UNet also emphasizes the images salient features through sophisticated attention mechanisms, including channel, spatial, and grouped gated attention. Our MK-UNet network, with a modest computational footprint of only 0.316M parameters and 0.314G FLOPs, represents not only a remarkably lightweight, but also significantly improved segmentation solution that provides higher accuracy over state-of-the-art (SOTA) methods across six binary medical imaging benchmarks. Specifically, MKUNet outperforms TransUNet in DICE score with nearly 333x and 123x fewer parameters and FLOPs, respectively. Similarly, when compared against UNeXt, MK-UNet exhibits superior segmentation performance, improving the DICE score up to 6.7% margins while operating with 4.7→fewer Params. Our MK-UNet also outperforms other recent lightweight networks, such as MedT, CMUNeXt, EGEUNet, and Rolling-UNet, with much lower computational resources. This leap in performance, coupled with drastic computational gains, positions MK-UNet as an unparalleled solution for real-time, high-fidelity medical diagnostics in resource-limited settings, such as point-of-care devices. Our implementation is available at https://github.com/SLDGroup/MK-UNet
Bib Citation
@inproceedings{rahman2025mk,
title={Mk-unet: Multi-kernel lightweight cnn for medical image segmentation},
author={Rahman, Md Mostafijur and Marculescu, Radu},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={1042--1051},
year={2025}
}Research Question / Problem Statement
- Varian UNet yang mengintegrasikan mekanisme atensi terbukti membantu memperbaiki feature maps, tetapi masih mekanisme itu terbatas pada kebutuhan resource yang besar.
- Vision Transformer memulai penggunaan self-attention yang menangkap dependensi yang panjang dan memberikan gambaran menyeluruh dari image. Tapi transformers melupakan menangkap relasi spatial lokal antar piksel.
- Transformer masih membutuhkan resource yang besar sehingga tidak praktikal.
- Penggabungan CNN + MLP masih sering digunakan untuk membuat model yang lebih lightwise, tapi masih terbatas pada task yang mudah seperti skin lession, breast cancer in ultrasound dan mikroskopic nuleus / strucktur segmentasi. Makanya model-model ini masih belum terlalu baik dalam task yang lebih kompleks.
Proposed Methods
Multi Kernel UNet menggunakan tiga komponen utama dalam membuat U-shaped network.
Methodology
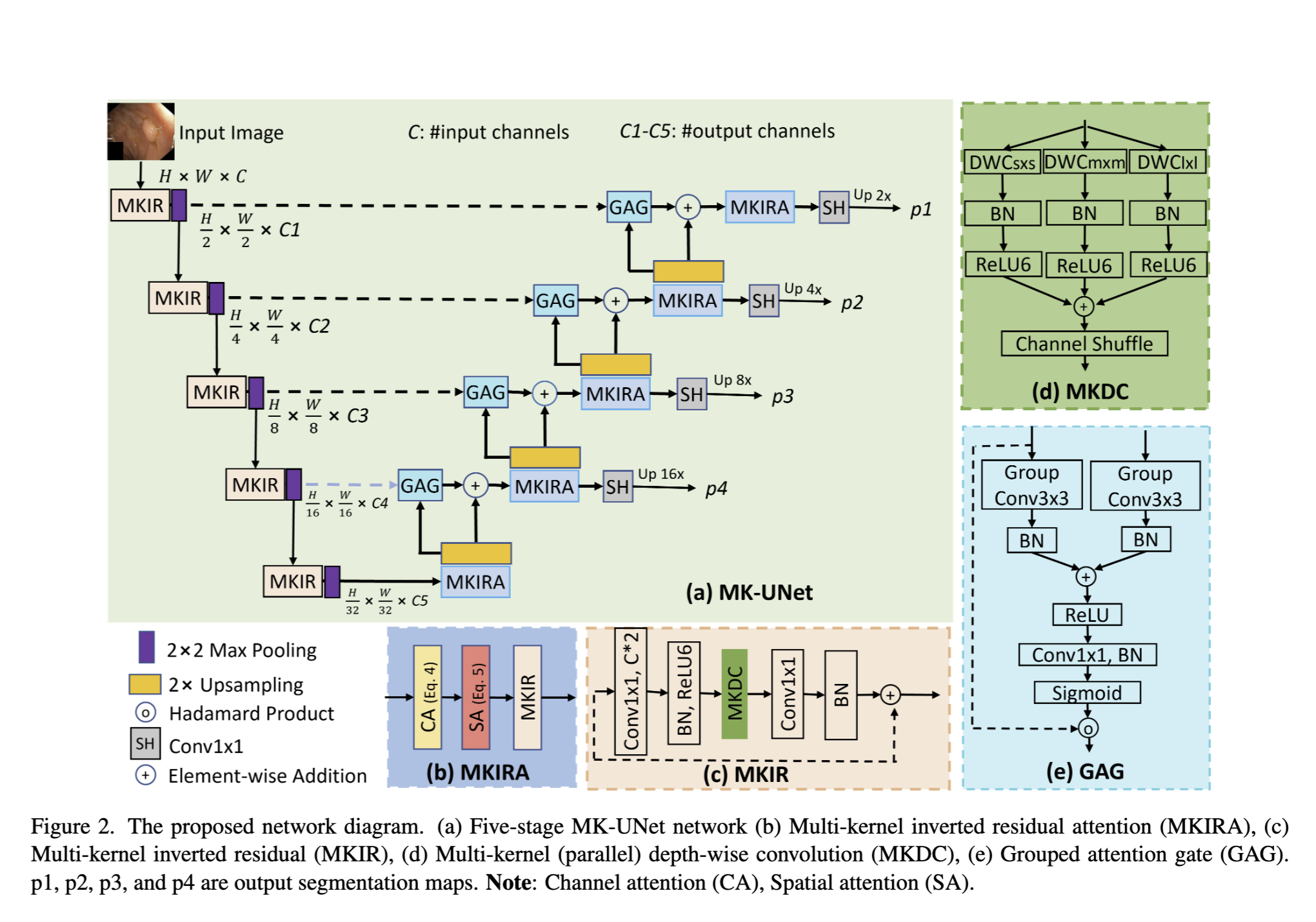
- Mengganti CNN pada blok U-Net Arch dg MKIR, MKIRA, GAG dan SH
- MKIR itu adalah satu unit dimana dia melakukan point-wise convolutional yang berfokus pada DepthWise Convoultional, berbeda dg paper terdahulu nya EMCAD